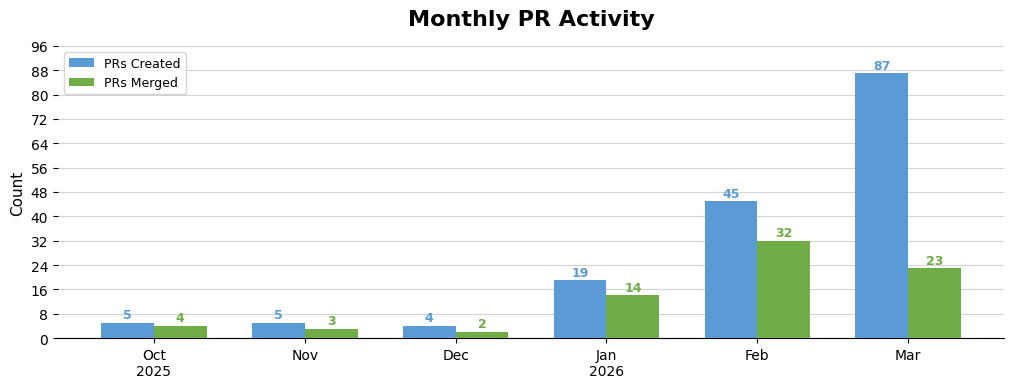
Last month I wrote my experience with AI-generated coding on this blog(two months as a vibe coder). I got a lot of positive feedback, so I created another chart for my work up till this months and wrote down the thoughts I had this month.
Overall first impression is that my amount of PRs went up once again, while my amount of merged PRs went down. The reason the amount of PRs went up is at the bottom of this article (automating solving problems), while the reason the amount of closed PRs went down is at the top (many PRs do stack up frustrations…)!
Free is not free
In the first two months I created PRs all over our codebase. This was great initially - people loved the new features I introduced, and problems I unblocked. However, slowly maintenance requests started coming in. This can be supporting another robotics platform in a dashboard, a small bug filtering wrong data, or a test not covering all test cases. Slowly but surely my days and work became dominated by features I was not planning to work on / didn’t consider when I made my initial changes.
Time will tell what the correct solution is. Should you redirect people who make a feature request to their own Cursor/Claude instances? Does an engineer collect features till the time they take to maintain features is equal to their workweek? Or should one team be responsible for maintaining a feature, but also be forced to review and consider any idea for which a pull request is made? The answer is probably “a mix of all three”.
With the concept of AI-generated code being so new I am still eager to personally own the code and features I introduce, but I’m lately less eager as I feel I filled the amount of features I can currently maintain.
Auto research is interesting
I have seen some hype around Karpathy’s auto-research. Basically you ask an AI to keep optimising a problem over and over and later investigate what solutions it found. Last month I set up multiple of these loops - both to speed up some processes, as well as to optimize my neural networks.
First of all: I did indeed find multiple code improvements! I merged multiple pull requests significantly speeding up development for everyone working with neural networks. However, I still have two problems with this approach. I am now less connected to the actual problems and code, and most of the attempted solutions were not super interesting.
While autoresearch did find ways to massively speed up my development I don’t have a good overview of where all of our time is going, and don’t have a good architecture in mind for the “optimal” solution. Autoresearch found a few bugs and features which massively reduced time, but did not give me a bigger idea of how we should set up our code to eliminate the issues in the first place. It does feel like I’m spending all my brain power finding a local minimum rather than rethinking how to get to a global minimum.
Besides that, I noticed that autoresearch mostly hangs on to existing hyperparameters and features. It’s eager to try changing the batch size or learning rate when training a neural network, but didn’t attempt to pre-train layers or do research on what the best state of the art encoders are. I’m still happy that it did the comparisons without me having to actively consider them, but I also notice that I did not spend enough time thinking for myself what the best high-level solution should be as I already saw autoresearch happily plodding along.
Last but not least: in my case autoresearch auto found some “exploits”. If you specify an objective but don’t specify what you can and can’t do the AI will naturally find ways which minimise a score, without actually achieving the objective. This is something we are used to with evolutionary algorithms, but I hoped that the ‘thinking’ aspect of LLMs would be more fair to how to achieve the objective.
Self made apps are better
This month I also got myself a Claude 20$ license (and immediately felt restricted with the amount of tokens I had…). I wrote and rewrote some things I made in the past, and really enjoyed the process! The best part of the process was the full control of any app functionality.
In the past if I did not like an app or feature I had to either reach out to the developer (and wait months to get it implemented, if even…), or dive into the source code myself (where even figuring out how to run/compile/host something was enough pain to deter me from it). By making an app from scratch you have full control over the functionality, even if the app might already exist somewhere else.
I think the future will be more apps with dynamic features, where users can request in natural language what a button should do. The app Bitrig is a fun thing to play with which feels like the future, but the default included model and permissions are so bad that it’s also immediately disappointing.
This doesn’t just go for apps, but also for frameworks. Where my previous blog used Wordpress this blog is completely created with help of Claude, and actually runs a lot faster than the previous blog! This month I heard multiple of my friends building interesting new tools for their own usage!
Big impact with a big bazooka
The reason my PR count is so large this month is that I tried auto-generating PRs for some types of issues. I managed to solve multiple problems which the authors/reviewers of the PR were not aware of. Overall it had a big impact. However, there were also some false positives (of which I closed the PRs as soon as I realised they were). That means there was some collateral damage. Overall in this case the positive outweighed the negative impact, but now that every software engineer (and others) has this power we will see what the impact is down the line!